Supplementary Figure 3. Evaluating validity of synthetic data generation scheme with respect to real patient data (removal of low frequency variants based on mean sequencing depth) To examine the specification of the synthetic data generation process, we iterated the VAF distribution feature vectors from each patient through the entire simulated training data set of 40 million synthetic tumours, searching for the nearest neighbours based on euclidean distance. We provide overlaid histograms of each patients VAF distribution with the closest nearest neighbour. All samples can be examined by using the dropdown menu. The feature vectors for this analysis were generated by using the mean sequencing depth to remove low frequency variants as described in Methods.
Supplementary Figure 4. Evaluating validity of synthetic data generation scheme with respect to real patient data (removal of low frequency variants based on mean effective coverage). To examine the specification of the synthetic data generation process, we iterated the VAF distribution feature vectors from each patient through the entire simulated training data set of 40 million synthetic tumours, searching for the nearest neighbours based on euclidean distance. We provide overlaid histograms of each patients VAF distribution with the closest nearest neighbour. All samples can be examined by using the dropdown menu. The feature vectors for this analysis were generated by using the mean effective coverage (mean sequencing depth * purity) to remove low frequency variants as described in Methods.
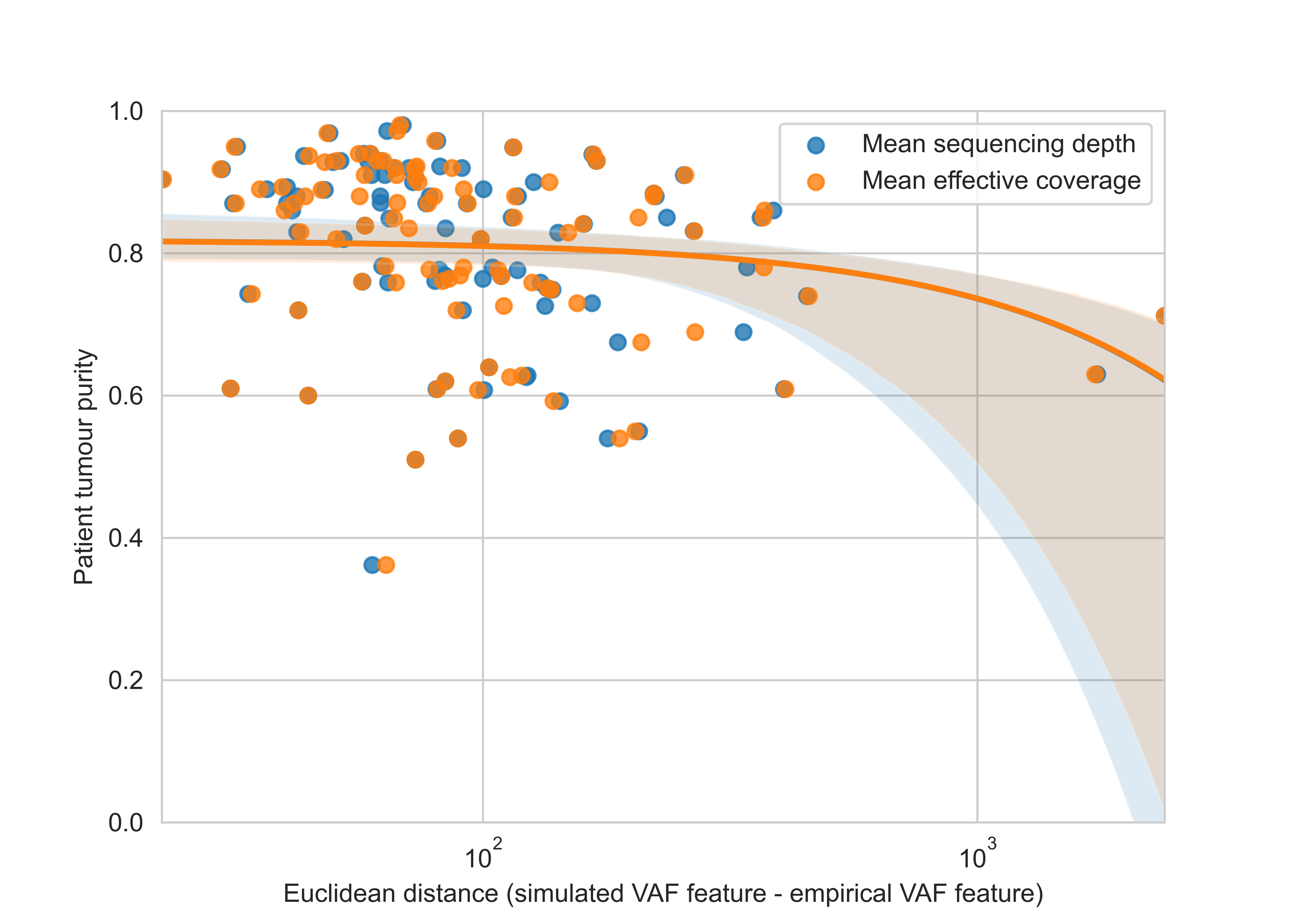
Supplementary Figure 5. Comparison of nearest neighbour search when using mean effective coverage versus mean sequencing depth. Using mean effective coverage (mean sequencing depth * purity) does not improve the fit between synthetic VAF distributions and patient tumour biopsy VAF distributions as defined by the euclidean distance of the nearest neighbour. Furthermore, samples only show modest increase in euclidean distance with decreasing purity which suggests the synthetic data generation scheme is robust to modest reductions in purity (e.g. > 0.5 analyzed in this study).